Analysis of Arrhythmia Classification on ECG Dataset
Introduction
In the realm of medical diagnostics, the accurate identification and classification of cardiac arrhythmias are of paramount importance. Cardiac arrhythmias encompass a range of irregular heart rhythms that can have serious implications for a patient's health. Detecting and classifying these arrhythmias swiftly and precisely is vital for effective patient care and treatment planning.
In recent years, the utilization of advanced data analysis techniques, particularly classification methods, has emerged as a promising avenue for improving the diagnosis of cardiac arrhythmias. These classification methods harness the power of machine learning and data science to analyze intricate arrhythmia data sets, offering healthcare professionals a more comprehensive understanding of the underlying patterns and trends.
This exploration delves into the application of classification methods to analyze arrhythmia data, with the goal of enhancing our ability to identify and differentiate various types of cardiac arrhythmias. By leveraging machine learning algorithms, such as decision trees, support vector machines, neural networks, and more, we aim to create accurate and efficient systems for arrhythmia classification. These systems not only have the potential to streamline diagnosis but also to provide valuable insights into the prognosis and treatment strategies for patients with cardiac arrhythmias.
Neural Networks
1. Training data with 2 classes
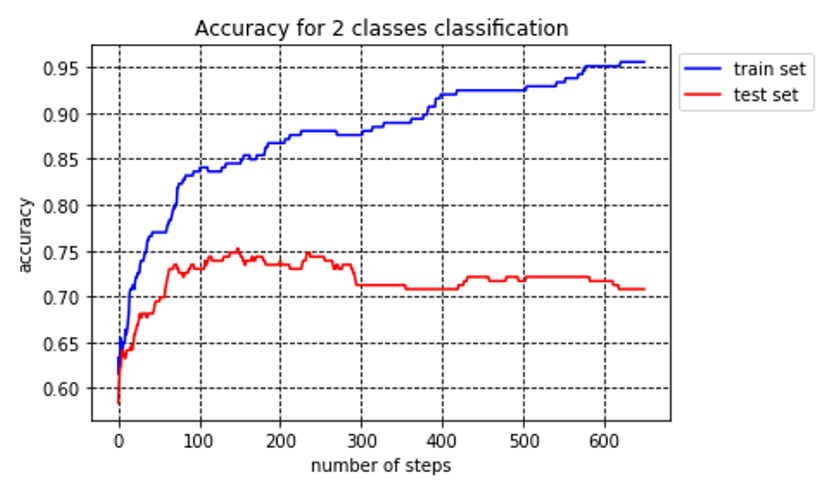
Firstly, we define the class, since the better activation function for two classes is sigmoid, the sigmoid output is the probability from 0 to 1. We define the class as class 0 (health) and class 1 (disease). We chose half of the data as a train set. By using the cross-entropy and sigmoid function, with a learning rate equal to 0.1, after training 650 times, the loss is equal to 0.18 and accuracy is equal to 95%, Using the same weight to test the test set, accuracy is around 71%, is better than minimum distance criterion and Bayes criterion. The process of the training is shown in the figure.
2. Training data with 16 classes
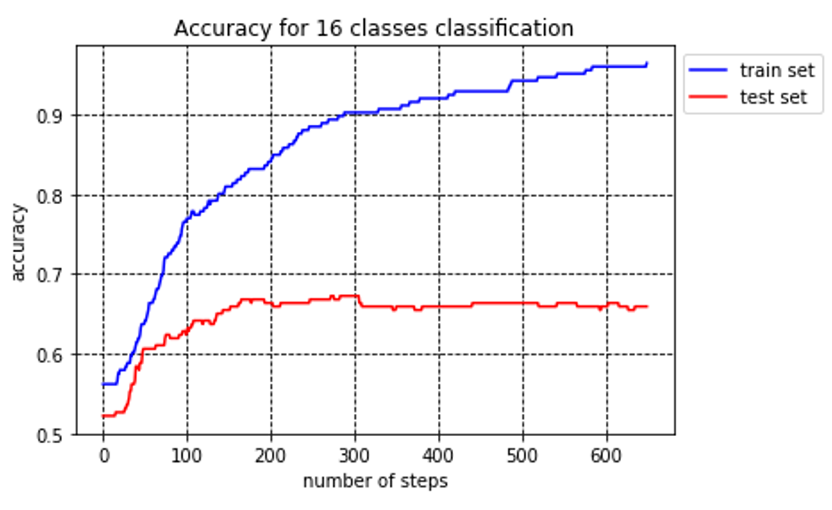
Use the same method, the only difference is using softmax activation instead of the sigmoid function to active neural. Before that, I changed the target matrix from one column to 16 columns, and marked the class as the biggest number in one sample, in order to take out the true class easily and compare it with the class that has the largest probability in the softmax function. After 650 times train, the loss is 0.19 and the accuracy is 96%. Memory this weight and bias, put it into the test set and we get 0.65% of accuracy. The process of training is shown in the figure.
Support vector machine
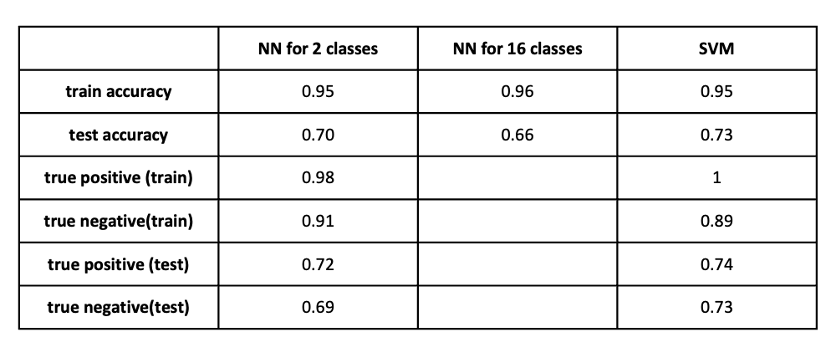
In the project, firstly we define the class lab as -1 and 1 according to the theory, then use PCA to find the principle component, use “sklearn” fit class label, and train and test set to get a list of the accuracy for each c from 0.1 to 3. Then choose number c which lets train accuracy larger than 90% and test accuracy as large as possible. Then I get the c is equal to 1.1. Use this value, fit the train and test set again, and get the estimated result.